A Hands-on Approach for Implementing Stochastic Optimization Algorithms from Scratch
Education Short Course
Important
This documentation is related to SC-1 Short Courses @ ICASSP’23.
Last update: June 9th, 2023.
Lecture slides are intended to be observed in presentation mode (full screen).
Partially supported by the Army Research Office (ARO) under Grant # W911NF-22-1-0296.
Course description
Summary
Gradient descent (GD) is a well-known first order optimization method, which uses the gradient of the loss function, along with a step-size (or learning rate), to iteratively update the solution. When the loss (cost) function is dependent on datasets with large cardinality, such in cases typically associated with deep learning (DL), GD becomes impractical.
In this scenario, stochastic GD (SGD), which uses a noisy gradient approximation (computed over a random fraction of the dataset), has become crucial. There exits several variants/improvements over the “vanilla” SGD, such RMSprop, Adagrad, Adadelta, Adam, Nadam, etc., which are usually given as black-boxes by most of DL’s libraries (TensorFlow, PyTorch, MXNet, etc.).
The primary objective of this course is to combined the essential theoretical aspects related to SGD and variants, along with hands on experience to program in Python, from scratch (i.e. not based on DL’s libraries such as TensorFlow, PyTorch, MXNet) the SGD along with the RMSprop, Adagrad, Adadelta, Adam and Nadam algorithms and to test their performance using the MNIST and CIFAR-10 datasets for shallow networks (consisting of up to two ReLU layers and a Softmax as the last layer).
Syllabus
Introduction
Basic concepts
Bayes’ theorem.
MAP (maximum a posteriori).
Linear regression.
Logistic and softmax regression.
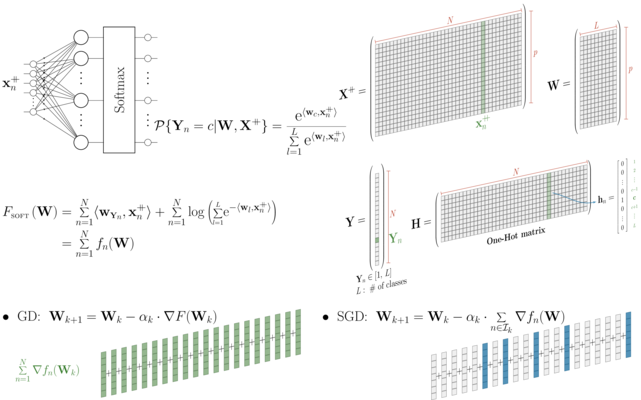
Gradient descent (GD) and stochastic GD.
Hands-on 1
The MNIST dataset.
Data preparation.
GD implementation; simple (quadratic) test.
SGD implementation; multiclass regression for the MNIST dataset.
Part A: Accelerated GD (AGD)
Adaptive step-sizes
Momentum.
Nesterov acceleration.
Anderson acceleration.
Hands-on 2.A
Accelerated GD implementation.
Comparisons w.r.t. GD.
Part B: SGD variants
Momentum (SGD-MTM)
Nesterov (SGD-NTRV)
SG Clipping (SGC)
Adagrad
Adadelta
RMSprop
Adam
AdaMax
Nadam
AdaBelief
SGD variants’ taxonomy
Hands-on 2.B
SGD variants implementation.
Multiclass regression for the MNIST dataset.
Part A: Hidden layers
Introduction.
Linear vs. non-linear.
Activation functions.
Hands-on 3.A
Impact of adding one, random value, ReLU hidden layer.
Classification of the MNIST dataset.
Classification of the CIFAR dataset.
Part B: Computing gradients
Introduction.
The backpropagation (BP) algorithm.
SGD and BP working together.
Hands-on 3.B
BP and SGD along with one ReLU hidden layer.
Classification of the CIFAR dataset.
Part A: Hands-on 4.A
BP and SGD along with two hidden layers / SGD variants.
Classification of the CIFAR dataset.
Part B: DL (deep learning) overview
Introduction.
Convolutional layer
Other layers: maxpool, dropout, dense, etc.
DL libraries: TensorFlow, PyTorch, MXNet.
Hands-on 4.B
Using TensorFlow (TF).
Performance comparison (w.r.t. Previously developed code).
Implementing your own solver in TF.
Using simple DL networks.